Page 52 - Fister jr., Iztok, and Andrej Brodnik (eds.). StuCoSReC. Proceedings of the 2017 4th Student Computer Science Research Conference. Koper: University of Primorska Press, 2017
P. 52
Subset existence Superset existence Subset existence Superset existence
order = descending order = descending
25000 |M| = 40000 25000 |M| = 40000 order = ascending 105 order = ascending
20000 |M| = 80000 20000 |M| = 80000 104
|M| = 160000 |M| = 160000 102 103 50 100 150 200 250
|M| = 320000 |M| = 320000 102 Length of input
|M| = 640000 |M| = 640000 0 50 100 150 200 250 101
Length of input 100
Visited nodes15000 15000 Visited nodes
Visited nodes Visited nodes 0
10000 10000
5000 5000
0 0
0 20 40 60 80 100 120 0 20 40 60 80 100 120
Length of input Length of input
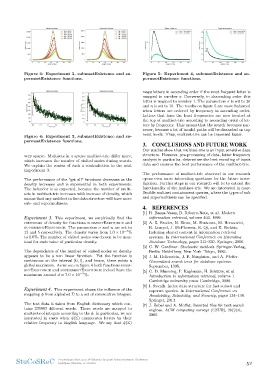
Figure 3: Experiment 2, submsetExistence and su- Figure 5: Experiment 4, submsetExistence and su-
permsetExistence functions. permsetExistence functions.
250 Subset existence 275 Superset existence maps letters in ascending order if the most frequent letter is
225 0.2 0.4Density, %0.6 0.8 250 0.2 0.4Density, %0.6 0.8 mapped to number σ. Conversely, in descending order this
Visited nodes200 225 letter is mapped to number 1. The parameters σ is set to 26
Visited nodes175200 and n is set to 10. The results on figure 5 are more balanced
150 175 when letters are ordered by frequency in ascending order.
125 1.0 150 1.0 Letters that have the least frequencies are now located at
100 125 the top of multiset-trie according to ascending order of let-
75 100 ters by frequency. This means that the search becomes nar-
75 rower, because a lot of invalid paths will be discarded on top
0.0 most levels. Thus, multiset-trie can be traversed faster.
0.0
3. CONCLUSIONS AND FUTURE WORK
Figure 4: Experiment 3, submsetExistence and su-
permsetExistence functions. Our studies show that multiset-trie is an input sensitive data
structure. However, pre-processing of data, letter frequency
very sparse. Multisets in a sparse multiset-trie differ more, analysis in particular, determines the best encoding of input
which increases the number of visited nodes during search. data and ensures the best performance of the multiset-trie.
We explain the reason of such a contradiction in the next
Experiment 3. The performance of multiset-trie observed in our research
opens even more interesting questions for the future inves-
The performance of the ”get all” functions decreases as the tigation. Further steps in our research will be to extend the
density increases and is exponential in both experiments. functionality of the multiset-trie. We are interested in more
The behavior is as expected, because the number of multi- flexible multiset containment queries, where the types of sub
sets in multiset-trie increases with increase of density, which and supermultisets can be specified.
means that any multiset in the data structure will have more
sub- and supermultisets. 4. REFERENCES
Experiment 3. This experiment, we empirically find the [1] R. Baeza-Yates, B. Ribeiro-Neto, et al. Modern
information retrieval, volume 463. 1999.
extremum of density for functions submsetExistence and
supermsetExistence. The parameters σ and n are set to [2] A. Z. Broder, N. Eiron, M. Fontoura, M. Herscovici,
12 and 5 respectively. The density varies from 1.0 × 10−4% R. Lempel, J. McPherson, R. Qi, and E. Shekita.
to 1.0%. The number of visited nodes was chosen to be max- Indexing shared content in information retrieval
imal for each value of particular density. systems. In International Conference on Extending
Database Technology, pages 313–330. Springer, 2006.
The dependence of the number of visited nodes on density
appears to be a non linear function. Yet the function is [3] C. W. Gardiner. Stochastic methods. Springer-Verlag,
continuous on the interval [0, 1], and hence, there exists a Berlin–Heidelberg–New York–Tokyo, 1985.
global maximum. As we see on figure 4 both functions subm-
setExistence and supermsetExistence indeed have the [4] J. M. Hellerstein, J. F. Naughton, and A. Pfeffer.
maximum around d ≈ 7.0 × 10−3%. Generalized search trees for database systems.
September, 1995.
Experiment 4. This experiment shows the influence of the
[5] C. D. Manning, P. Raghavan, H. Schu¨tze, et al.
mapping φ from alphabet Σ to a set of consecutive integers. Introduction to information retrieval, volume 1.
Cambridge university press Cambridge, 2008.
The test data is taken from English dictionary which con-
tains 235883 different words. Those words are mapped to [6] I. Savnik. Index data structure for fast subset and
multisets of integers according to the φ. In particular, we are superset queries. In International Conference on
interested in cases when φ(Σ) enumerates letters by their Availability, Reliability, and Security, pages 134–148.
relative frequency in English language. We say that φ(Σ) Springer, 2013.
[7] J. Zobel and A. Moffat. Inverted files for text search
engines. ACM computing surveys (CSUR), 38(2):6,
2006.
StuCoSReC Proceedings of the 2017 4th Student Computer Science Research Conference 52
Ljubljana, Slovenia, 11 October
order = descending order = descending
25000 |M| = 40000 25000 |M| = 40000 order = ascending 105 order = ascending
20000 |M| = 80000 20000 |M| = 80000 104
|M| = 160000 |M| = 160000 102 103 50 100 150 200 250
|M| = 320000 |M| = 320000 102 Length of input
|M| = 640000 |M| = 640000 0 50 100 150 200 250 101
Length of input 100
Visited nodes15000 15000 Visited nodes
Visited nodes Visited nodes 0
10000 10000
5000 5000
0 0
0 20 40 60 80 100 120 0 20 40 60 80 100 120
Length of input Length of input
Figure 3: Experiment 2, submsetExistence and su- Figure 5: Experiment 4, submsetExistence and su-
permsetExistence functions. permsetExistence functions.
250 Subset existence 275 Superset existence maps letters in ascending order if the most frequent letter is
225 0.2 0.4Density, %0.6 0.8 250 0.2 0.4Density, %0.6 0.8 mapped to number σ. Conversely, in descending order this
Visited nodes200 225 letter is mapped to number 1. The parameters σ is set to 26
Visited nodes175200 and n is set to 10. The results on figure 5 are more balanced
150 175 when letters are ordered by frequency in ascending order.
125 1.0 150 1.0 Letters that have the least frequencies are now located at
100 125 the top of multiset-trie according to ascending order of let-
75 100 ters by frequency. This means that the search becomes nar-
75 rower, because a lot of invalid paths will be discarded on top
0.0 most levels. Thus, multiset-trie can be traversed faster.
0.0
3. CONCLUSIONS AND FUTURE WORK
Figure 4: Experiment 3, submsetExistence and su-
permsetExistence functions. Our studies show that multiset-trie is an input sensitive data
structure. However, pre-processing of data, letter frequency
very sparse. Multisets in a sparse multiset-trie differ more, analysis in particular, determines the best encoding of input
which increases the number of visited nodes during search. data and ensures the best performance of the multiset-trie.
We explain the reason of such a contradiction in the next
Experiment 3. The performance of multiset-trie observed in our research
opens even more interesting questions for the future inves-
The performance of the ”get all” functions decreases as the tigation. Further steps in our research will be to extend the
density increases and is exponential in both experiments. functionality of the multiset-trie. We are interested in more
The behavior is as expected, because the number of multi- flexible multiset containment queries, where the types of sub
sets in multiset-trie increases with increase of density, which and supermultisets can be specified.
means that any multiset in the data structure will have more
sub- and supermultisets. 4. REFERENCES
Experiment 3. This experiment, we empirically find the [1] R. Baeza-Yates, B. Ribeiro-Neto, et al. Modern
information retrieval, volume 463. 1999.
extremum of density for functions submsetExistence and
supermsetExistence. The parameters σ and n are set to [2] A. Z. Broder, N. Eiron, M. Fontoura, M. Herscovici,
12 and 5 respectively. The density varies from 1.0 × 10−4% R. Lempel, J. McPherson, R. Qi, and E. Shekita.
to 1.0%. The number of visited nodes was chosen to be max- Indexing shared content in information retrieval
imal for each value of particular density. systems. In International Conference on Extending
Database Technology, pages 313–330. Springer, 2006.
The dependence of the number of visited nodes on density
appears to be a non linear function. Yet the function is [3] C. W. Gardiner. Stochastic methods. Springer-Verlag,
continuous on the interval [0, 1], and hence, there exists a Berlin–Heidelberg–New York–Tokyo, 1985.
global maximum. As we see on figure 4 both functions subm-
setExistence and supermsetExistence indeed have the [4] J. M. Hellerstein, J. F. Naughton, and A. Pfeffer.
maximum around d ≈ 7.0 × 10−3%. Generalized search trees for database systems.
September, 1995.
Experiment 4. This experiment shows the influence of the
[5] C. D. Manning, P. Raghavan, H. Schu¨tze, et al.
mapping φ from alphabet Σ to a set of consecutive integers. Introduction to information retrieval, volume 1.
Cambridge university press Cambridge, 2008.
The test data is taken from English dictionary which con-
tains 235883 different words. Those words are mapped to [6] I. Savnik. Index data structure for fast subset and
multisets of integers according to the φ. In particular, we are superset queries. In International Conference on
interested in cases when φ(Σ) enumerates letters by their Availability, Reliability, and Security, pages 134–148.
relative frequency in English language. We say that φ(Σ) Springer, 2013.
[7] J. Zobel and A. Moffat. Inverted files for text search
engines. ACM computing surveys (CSUR), 38(2):6,
2006.
StuCoSReC Proceedings of the 2017 4th Student Computer Science Research Conference 52
Ljubljana, Slovenia, 11 October