Page 81 - Fister jr., Iztok, Andrej Brodnik, Matjaž Krnc and Iztok Fister (eds.). StuCoSReC. Proceedings of the 2019 6th Student Computer Science Research Conference. Koper: University of Primorska Press, 2019
P. 81
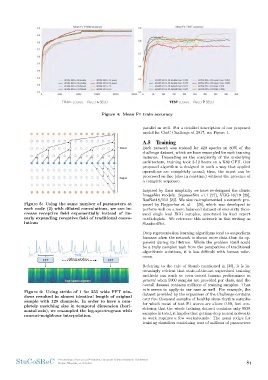
ure 4: Mean F1 train accuracy
Dilated parallel as well. For a detailed description of our proposed
model for CinC Challenge of 2017, see Figure 1.
Original
A.5 Training
Figure 5: Using the same number of parameters at
each node (2) with dilated convolutions, we can in- Each network was trained for 420 epochs on 80% of the
crease receptive field exponentially instead of lin- challenge dataset, which we have resampled for each training
early expanding receptive field of traditional convo- instance. Depending on the complexity of the underlying
lutions architecture, training took 3-12 hours on a K80 GPU. Our
proposed algorithm is designed in such a way that applied
TIME operations are completely causal; thus, the input can be
FFT sliding window FFT processed on-line (also in real-time) without the presence of
a complete sequence.
log-spectrogram
Inspired by their simplicity we have re-designed the classic
Figure 6: Using stride of 1 for 255 wide FFT win- ImageNet models: SqueezeNet v1.1 [27], VGG-16/19 [28],
dows resulted in almost identical length of original ResNet18/152 [23]. We also re-implemented a network pro-
sample with 128 channels. In order to have a com- posed by Rajpurkar et al. [29], which was developed to
pletely matching size in temporal dimension (hori- perform well on a more balanced dataset of over sixty thou-
zontal axis), we resampled the log-spectrogram with sand single lead ECG samples, annotated by lead expert
nearest-neighbour interpolation. cardiologists. We reference this network in this writing as
StanfordNet.
Deep representation learning algorithms tend to outperform
humans when the network is shown more data than its op-
ponent during its lifetime. While the problem itself could
be a truly complex task from the perspective of traditional
algorithmic solutions, it is less difficult with human refer-
ences.
Referring to the rule of thumb mentioned in [30], it is in-
creasingly evident that state-of-the-art supervised training
methods can reach or even exceed human performance in
general when 5000 samples are provided per class, and the
overall dataset contains millions of training samples. That
rule seems to apply to our case as well. For example, the
dataset provided by the organizers of the Challenge contains
over five thousand samples of healthy sinus-rhythm samples
for which mean of test F1 scores are above 0.90, but con-
sidering that the whole training dataset contains only 8528
samples in total, it implies that getting deep neural networks
to work requires a few workarounds. The usual recipe for
training classifiers containing tens of millions of parameters
StuCoSReC Proceedings of the 2019 6th Student Computer Science Research Conference 81
Koper, Slovenia, 10 October
Dilated parallel as well. For a detailed description of our proposed
model for CinC Challenge of 2017, see Figure 1.
Original
A.5 Training
Figure 5: Using the same number of parameters at
each node (2) with dilated convolutions, we can in- Each network was trained for 420 epochs on 80% of the
crease receptive field exponentially instead of lin- challenge dataset, which we have resampled for each training
early expanding receptive field of traditional convo- instance. Depending on the complexity of the underlying
lutions architecture, training took 3-12 hours on a K80 GPU. Our
proposed algorithm is designed in such a way that applied
TIME operations are completely causal; thus, the input can be
FFT sliding window FFT processed on-line (also in real-time) without the presence of
a complete sequence.
log-spectrogram
Inspired by their simplicity we have re-designed the classic
Figure 6: Using stride of 1 for 255 wide FFT win- ImageNet models: SqueezeNet v1.1 [27], VGG-16/19 [28],
dows resulted in almost identical length of original ResNet18/152 [23]. We also re-implemented a network pro-
sample with 128 channels. In order to have a com- posed by Rajpurkar et al. [29], which was developed to
pletely matching size in temporal dimension (hori- perform well on a more balanced dataset of over sixty thou-
zontal axis), we resampled the log-spectrogram with sand single lead ECG samples, annotated by lead expert
nearest-neighbour interpolation. cardiologists. We reference this network in this writing as
StanfordNet.
Deep representation learning algorithms tend to outperform
humans when the network is shown more data than its op-
ponent during its lifetime. While the problem itself could
be a truly complex task from the perspective of traditional
algorithmic solutions, it is less difficult with human refer-
ences.
Referring to the rule of thumb mentioned in [30], it is in-
creasingly evident that state-of-the-art supervised training
methods can reach or even exceed human performance in
general when 5000 samples are provided per class, and the
overall dataset contains millions of training samples. That
rule seems to apply to our case as well. For example, the
dataset provided by the organizers of the Challenge contains
over five thousand samples of healthy sinus-rhythm samples
for which mean of test F1 scores are above 0.90, but con-
sidering that the whole training dataset contains only 8528
samples in total, it implies that getting deep neural networks
to work requires a few workarounds. The usual recipe for
training classifiers containing tens of millions of parameters
StuCoSReC Proceedings of the 2019 6th Student Computer Science Research Conference 81
Koper, Slovenia, 10 October