Page 82 - Fister jr., Iztok, Andrej Brodnik, Matjaž Krnc and Iztok Fister (eds.). StuCoSReC. Proceedings of the 2019 6th Student Computer Science Research Conference. Koper: University of Primorska Press, 2019
P. 82
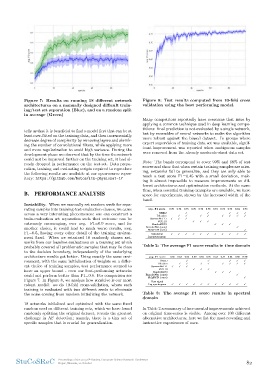
ure 7: Results on running 18 different network Figure 8: Test results computed from 10-fold cross
architectures on a manually designed difficult train- validation using the best performing model.
ing/test set separation (Blue), and on a random split
in average (Green) Many competitors reportedly have overcome that issue by
applying a common technique used in deep learning compe-
tells us that it is beneficial to find a model first that can be at titions: final prediction is not evaluated by a single network,
least over-fitted on the training data, and then incrementally but by ensembles of neural networks to make the algorithm
decrease degree of complexity by removing layers and shrink- more robust against the biased dataset. In groups where
ing the number of convolutional filters, while applying more expert supervision of training data set was available, signif-
and more regularization to avoid high variance. During the icant improvement was reported when ambiguous samples
development phase we observed that by the time the network were removed from the already moderate-sized data set.
could not be improved further on the training set, it had al-
ready dropped in performance on the test set. Data prepa- Note: The bands correspond to cover 99% and 68% of test
ration, training and evaluating scripts required to reproduce scores and show that when certain training samples are miss-
the following results are available at our open-source repos- ing, networks fail to generalize, and they are only able to
itory: https://github.com/botcs/itk-physionet-17 reach a test score F1=0.45 with a small deviation, mak-
ing it almost impossible to measure improvements on dif-
B. PERFORMANCE ANALYSIS ferent architectures and optimization methods. At the same
time, when essential training examples are available, we have
Instability. When we manually set random seeds for sepa- space for experiments, shown by the increased width of the
band.
rating samples into training-test-evaluation classes, we came
across a very interesting phenomenon: one can construct a avg. F1 score 0.70 0.72 0.73 0.72 0.76 0.78 0.74 0.74 0.75 0.81 0.73
train-evaluation set separation such that outcome can be SELU
extremely encouraging, over avg. F1=0.9 score, and for
another choice, it could lead to much worse results, avg. Dilation
F1=0.5, having every other detail of the training environ- SqueezeNet 1.1
ment fixed. When we retrained 18 randomly chosen net-
works from our baseline evaluations on a training set which VGG 19
probably covered all problematic samples that may lie close StanfordECG
to the decision boundary, independently of the underlying EncodeNet (ours)
architecture results got better. Using exactly the same envi- SkipFCN (ours)
ronment, with the same initialization of weights on a differ- Raw signal
ent choice of training samples, test performance seemed to Log-spectrogram
have an upper bound - even our best-performing networks
could not perform better than F1=0.6. For comparison see Table 2: The average F1 score results in time domain
Figure 7. In Figure 8, we analyze how sensitive is our most
robust model: we do 10-fold cross-validation, where each avg. F1 score 0.65 0.63 0.63 0.69 0.74 0.75 0.53 0.51 0.54 0.68 0.79
training is evaluated with two different seeds to eliminate SELU
the noise coming from random initializing the network.
Dilation
18 networks initialized and optimized with the same fixed SqueezeNet 1.1
random seed on different training sets, which we have found
randomly splitting the original dataset, reveals the greatest VGG 19
challenge in AF detection; namely, there is a tiny set of StanfordECG
specific samples that is crucial for generalization. EncodeNet (ours)
SkipFCN (ours)
Raw signal
Log-spectrogram
Table 3: The average F1 score results in spectral
domain
In Table 2 a summary of incremental improvements achieved
on original time-series is visible. Among over 100 different
alternative architectures, here we list the most revealing and
instructive experiences of ours.
StuCoSReC Proceedings of the 2019 6th Student Computer Science Research Conference 82
Koper, Slovenia, 10 October
architectures on a manually designed difficult train- validation using the best performing model.
ing/test set separation (Blue), and on a random split
in average (Green) Many competitors reportedly have overcome that issue by
applying a common technique used in deep learning compe-
tells us that it is beneficial to find a model first that can be at titions: final prediction is not evaluated by a single network,
least over-fitted on the training data, and then incrementally but by ensembles of neural networks to make the algorithm
decrease degree of complexity by removing layers and shrink- more robust against the biased dataset. In groups where
ing the number of convolutional filters, while applying more expert supervision of training data set was available, signif-
and more regularization to avoid high variance. During the icant improvement was reported when ambiguous samples
development phase we observed that by the time the network were removed from the already moderate-sized data set.
could not be improved further on the training set, it had al-
ready dropped in performance on the test set. Data prepa- Note: The bands correspond to cover 99% and 68% of test
ration, training and evaluating scripts required to reproduce scores and show that when certain training samples are miss-
the following results are available at our open-source repos- ing, networks fail to generalize, and they are only able to
itory: https://github.com/botcs/itk-physionet-17 reach a test score F1=0.45 with a small deviation, mak-
ing it almost impossible to measure improvements on dif-
B. PERFORMANCE ANALYSIS ferent architectures and optimization methods. At the same
time, when essential training examples are available, we have
Instability. When we manually set random seeds for sepa- space for experiments, shown by the increased width of the
band.
rating samples into training-test-evaluation classes, we came
across a very interesting phenomenon: one can construct a avg. F1 score 0.70 0.72 0.73 0.72 0.76 0.78 0.74 0.74 0.75 0.81 0.73
train-evaluation set separation such that outcome can be SELU
extremely encouraging, over avg. F1=0.9 score, and for
another choice, it could lead to much worse results, avg. Dilation
F1=0.5, having every other detail of the training environ- SqueezeNet 1.1
ment fixed. When we retrained 18 randomly chosen net-
works from our baseline evaluations on a training set which VGG 19
probably covered all problematic samples that may lie close StanfordECG
to the decision boundary, independently of the underlying EncodeNet (ours)
architecture results got better. Using exactly the same envi- SkipFCN (ours)
ronment, with the same initialization of weights on a differ- Raw signal
ent choice of training samples, test performance seemed to Log-spectrogram
have an upper bound - even our best-performing networks
could not perform better than F1=0.6. For comparison see Table 2: The average F1 score results in time domain
Figure 7. In Figure 8, we analyze how sensitive is our most
robust model: we do 10-fold cross-validation, where each avg. F1 score 0.65 0.63 0.63 0.69 0.74 0.75 0.53 0.51 0.54 0.68 0.79
training is evaluated with two different seeds to eliminate SELU
the noise coming from random initializing the network.
Dilation
18 networks initialized and optimized with the same fixed SqueezeNet 1.1
random seed on different training sets, which we have found
randomly splitting the original dataset, reveals the greatest VGG 19
challenge in AF detection; namely, there is a tiny set of StanfordECG
specific samples that is crucial for generalization. EncodeNet (ours)
SkipFCN (ours)
Raw signal
Log-spectrogram
Table 3: The average F1 score results in spectral
domain
In Table 2 a summary of incremental improvements achieved
on original time-series is visible. Among over 100 different
alternative architectures, here we list the most revealing and
instructive experiences of ours.
StuCoSReC Proceedings of the 2019 6th Student Computer Science Research Conference 82
Koper, Slovenia, 10 October