Page 64 - Fister jr., Iztok, and Andrej Brodnik (eds.). StuCoSReC. Proceedings of the 2018 5th Student Computer Science Research Conference. Koper: University of Primorska Press, 2018
P. 64
not in practice. The LSTM have been developed to zt = σ(Wz ∗ ht−1 + Uf ∗ xt)
avoid classic RNN problem about memory-cell and can han- rt = σ(Wr ∗ ht−1 + Ui ∗ xt)
dle the long-range dependencies. ht = tanh (W ∗ [ht−1 ∗ rt] + W ∗ xt)
LSTM was introduced in 1997 by Sepp Hochrieiter and Ju¨r- ht = (1 − zt) ∗ ht−1 + zt ∗ ht
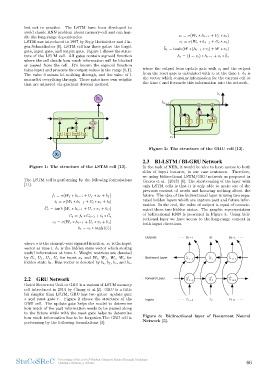
gen Schmidhuber [8]. LSTM cell has three gates: the forget
gate, input gate, and output gate. Figure 1 shows the struc- where the output from update gate with zt and the output
ture of the LSTM cell. All gates contain sigmoid function from the reset gate is calculated with rt at the time t. ht is
where the cell decide how much information will be blocked the vector which contains information for the current cell at
or passed from the cell. It’s known the sigmoid function the time t and forwards this information into the network.
takes input and presents the output values in the range [0,1].
The value 0 means let nothing through, and the value of 1
means let everything through. These gates have own weights
that are adjusted via gradient descent method.
Figure 1: The structure of the LSTM cell [13]. Figure 2: The structure of the GRU cell [13].
The LSTM cell is performing by the following formulations 2.3 BI-LSTM / BI-GRU Network
[11]:
In the task of NER, it would be nice to have access to both
ft = σ(Wf ∗ ht−1 + Uf ∗ xt + bf ) sides of input features, in our case sentences. Therefore,
it = σ(Wi ∗ ht−1 + Ui ∗ xt + bi) we using bidirectional LSTM/GRU network as proposed in
Graves et al. (2013) [6]. The shortcoming of the layer with
Ct = tanh (Wc ∗ ht−1 + Uc ∗ xt + bC ) only LSTM cells is that it is only able to make use of the
Ct = ft ∗ Ct−1 + it ∗ Ct previous context of words and knowing nothing about the
future. The idea of the bidirectional layer is using two sepa-
ot = σ(Wo ∗ ht−1 + Uo ∗ xt + bo) rated hidden layers which are capture past and future infor-
ht = ot ∗ tanh (Ct) mation. In the end, the value of output is equal of concate-
nated these two hidden states. The graphic representation
of bidirectional RNN is presented in Figure 3. Using bidi-
rectional layer we have access to the long-range context in
both input directions.
where σ is the element-wise sigmoid function. xt is the input
vector at time t. ht is the hidden state vector which storing
useful information at time t. Weight matrices are denoted
by Ui, Uf , Uc, Uo for input xt and Wi, Wf , Wc, Wo for
hidden state ht. Bias vector is denoted by bi, bf , bc, and bo.
2.2 GRU Network Figure 3: Bidirectional layer of Recurrent Neural
Network [5].
Gated Recurrent Unit or GRU is a variant of LSTM memory
cell introduced in 2014 by Chung et al.[2]. GRU is a little
bit simpler than LSTM, GRU has two gates: update gate
z and reset gate r. Figure 2 shows the structure of the
GRU cell. The update gate helps the model to determine
how much of the past information needs to be passed along
to the future while with the reset gate helps to determine
how much information has to be forgotten.The GRU cell is
performing by the following formulations [3]:
StuCoSReC Proceedings of the 2018 5th Student Computer Science Research Conference 66
Ljubljana, Slovenia, 9 October
avoid classic RNN problem about memory-cell and can han- rt = σ(Wr ∗ ht−1 + Ui ∗ xt)
dle the long-range dependencies. ht = tanh (W ∗ [ht−1 ∗ rt] + W ∗ xt)
LSTM was introduced in 1997 by Sepp Hochrieiter and Ju¨r- ht = (1 − zt) ∗ ht−1 + zt ∗ ht
gen Schmidhuber [8]. LSTM cell has three gates: the forget
gate, input gate, and output gate. Figure 1 shows the struc- where the output from update gate with zt and the output
ture of the LSTM cell. All gates contain sigmoid function from the reset gate is calculated with rt at the time t. ht is
where the cell decide how much information will be blocked the vector which contains information for the current cell at
or passed from the cell. It’s known the sigmoid function the time t and forwards this information into the network.
takes input and presents the output values in the range [0,1].
The value 0 means let nothing through, and the value of 1
means let everything through. These gates have own weights
that are adjusted via gradient descent method.
Figure 1: The structure of the LSTM cell [13]. Figure 2: The structure of the GRU cell [13].
The LSTM cell is performing by the following formulations 2.3 BI-LSTM / BI-GRU Network
[11]:
In the task of NER, it would be nice to have access to both
ft = σ(Wf ∗ ht−1 + Uf ∗ xt + bf ) sides of input features, in our case sentences. Therefore,
it = σ(Wi ∗ ht−1 + Ui ∗ xt + bi) we using bidirectional LSTM/GRU network as proposed in
Graves et al. (2013) [6]. The shortcoming of the layer with
Ct = tanh (Wc ∗ ht−1 + Uc ∗ xt + bC ) only LSTM cells is that it is only able to make use of the
Ct = ft ∗ Ct−1 + it ∗ Ct previous context of words and knowing nothing about the
future. The idea of the bidirectional layer is using two sepa-
ot = σ(Wo ∗ ht−1 + Uo ∗ xt + bo) rated hidden layers which are capture past and future infor-
ht = ot ∗ tanh (Ct) mation. In the end, the value of output is equal of concate-
nated these two hidden states. The graphic representation
of bidirectional RNN is presented in Figure 3. Using bidi-
rectional layer we have access to the long-range context in
both input directions.
where σ is the element-wise sigmoid function. xt is the input
vector at time t. ht is the hidden state vector which storing
useful information at time t. Weight matrices are denoted
by Ui, Uf , Uc, Uo for input xt and Wi, Wf , Wc, Wo for
hidden state ht. Bias vector is denoted by bi, bf , bc, and bo.
2.2 GRU Network Figure 3: Bidirectional layer of Recurrent Neural
Network [5].
Gated Recurrent Unit or GRU is a variant of LSTM memory
cell introduced in 2014 by Chung et al.[2]. GRU is a little
bit simpler than LSTM, GRU has two gates: update gate
z and reset gate r. Figure 2 shows the structure of the
GRU cell. The update gate helps the model to determine
how much of the past information needs to be passed along
to the future while with the reset gate helps to determine
how much information has to be forgotten.The GRU cell is
performing by the following formulations [3]:
StuCoSReC Proceedings of the 2018 5th Student Computer Science Research Conference 66
Ljubljana, Slovenia, 9 October